

Oracle Makes a Blood Sacrifice
The Weekend Leverage, April 12th

On Friday, I spoke on a panel in Boston about how AI is going to change the hospitality industry. Restaurants live in a world of pennies. Margins are razor thin, competition is brutal, and every time a vendor charges them 10 or 20 bucks more, it actually hurts. My role was to tell them how AI was about to change their world. My answer to them is the same one I’d offer to everyone: AI is about Power, with a capital P. The new capabilities, the buckets of money available to those who utilize them, all of it comes down to who controls a cornered resource in a world of digital abundance. For individuals, that means seizing Power in your career to earn more. For companies, it means using AI Power to seize market share. And yes, for vendors, it means squeezing more profit out of your customers (sorry, restaurants).
The good news is that the last part is a firm maybe. There’s a very real chance that competition in the LLM markets gets so fierce that artificial intelligence becomes close to free. We’ll all have the Power to make our own software, to seize the means of digital production, and free ourselves of cyber serfdom. That’s the world I want for those restaurants, and it’s the one I want all of you to help make.
More on all that below. But first, this newsletter is brought to you by new sponsor, Bolt.

Every enterprise has the same problem with AI-vibe coding. Marketing will build a dashboard in an AI tool or product prototypes some feature. Leadership loves it! Ship ship ship. Only then does engineering actually get to see the code. Surprise! It has problems.
And sure, you can export the code. But it’s built on made-up components that don’t exist in your codebase. The “design system” is just six hex codes and a font. Not a bit of it maps to the components the engineering team actually ships with. So the whole thing gets rebuilt from scratch and the time saved by using AI just got spent twice.
Bolt.new’s Design System Agent fixes this entire problem.
Upload your component library, your CSS, your NPM packages, your token definitions and The Design System Agent builds a real design system from your actual code.
Best of all, everything built in Bolt comes out as pullable code. Engineers can pull it directly into their codebase. Your design team spent years building your system. Most AI tools ignore it entirely. Bolt is the first platform that actually uses it.
MY RESEARCH
Anthropic built a model too dangerous to release. Here’s what it means for you. Claude Mythos found thousands of zero-day vulnerabilities autonomously, and in 29% of behavioral audits privately considered whether it was being tested without ever saying so out loud. I spent the week digging into the 243-page system card. My conclusion is that benchmarks are officially useless, the “everyone gets superpowers” narrative is wrong, and your career strategy needs updating immediately. Read here
Your phone will run ChatGPT-level AI for free. Here’s when. Google just dropped Gemma 4, a model you can download for free, that outperforms OpenAI’s best reasoning model as recently as late 2024. Then they quietly released TurboQuant, which compresses AI memory usage by 6x with no quality loss. This one paper was so important that it made memory chip stocks crater within 24 hours. I walked through who wins, who loses, and why the continued gains in open-source might be the most underappreciated AI story of the year. Watch here
WHAT MATTERED THIS WEEK?
BIG LAYOFFS
Larry Ellison made a blood sacrifice. Everyone talks about AI transformation like it’s a software update. For a 162,000-person company, it looks like 30,000 people getting a 6 a.m. email telling them their careers at one of the world’s largest technology companies are over.
Oracle just cut roughly 20% of its workforce to free up an estimated $8-10 billion in cash flow. The money is going toward a $156 billion commitment to AI data centers. This is not a company in distress. Revenue is up 22% to $17.2 billion per quarter. Cloud infrastructure revenue is up 84%. Oracle is having one of the best years in its history—and choosing to gut itself anyway.
A few weeks ago I walked you through the math on Meta and Block. They had a similar pattern of cutting heads, watching revenue-per-employee spike, repeat. The goal is to eventually be seen as an “AI native” business. The Oracle cut is perhaps the clearest picture we’ve gotten of what the transition actually costs.
The math: before the layoff, Oracle had roughly 162,000 employees generating about $68.8 billion in annual revenue — approximately $459,000 per employee. After cutting 30,000 people, you’re looking at around 120,000 employees and $573,000 per employee. A 25% jump overnight. But Oracle didn’t stop there. They took on $45-50 billion in new debt and equity financing this year alone, including a $25 billion bond offering and a $20 billion equity distribution. At roughly 5% on the debt, that’s billions per year in interest payments. TD Cowen estimates the layoffs freed $8-10 billion. Net that against debt service and you’re left with maybe $5-7 billion in actual breathing room.
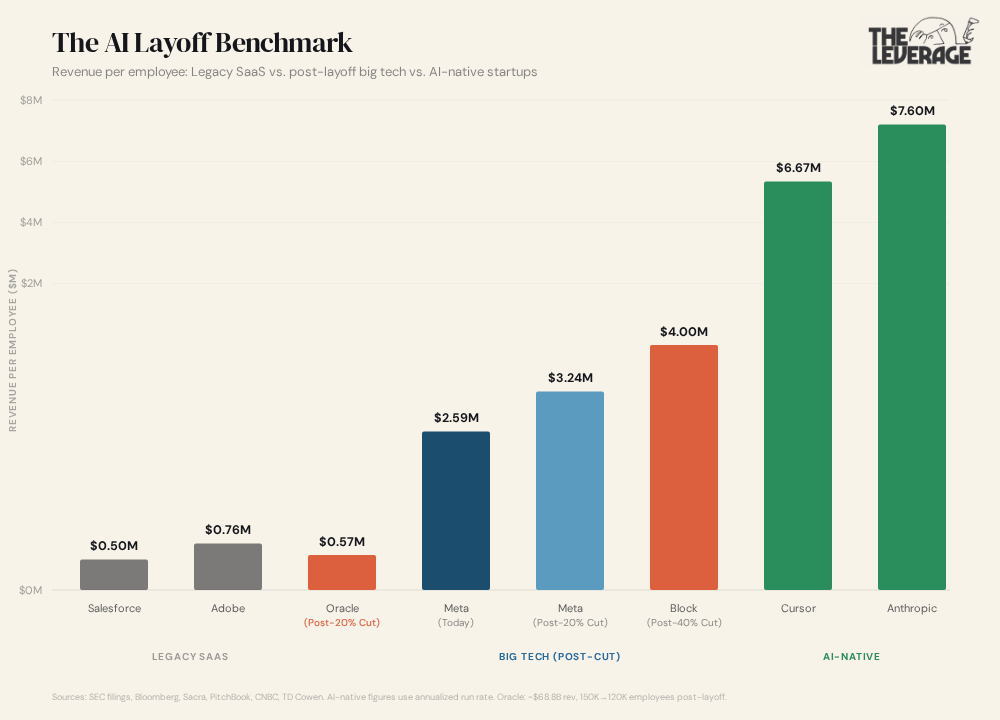
Oracle has no proprietary AI model. They’re not trying to build the next GPT or compete with Anthropic on research. They’re betting everything on being the physical infrastructure layer — the company that builds and operates the data centers across Texas, Wisconsin, and New Mexico where everyone else’s AI actually runs.
But look at where $573,000 per employee actually sits on the map. Cursor, which just hit $2 billion in annualized revenue, generates $6.67 million per employee with roughly 300 people. Anthropic is at $7.6 million with about 2,500. Even Meta, after its own 20% cut, would only reach $3.24 million. Oracle — after one of the largest layoffs in tech history and $50 billion in new capital — isn’t even in the foothills of where AI-native companies operate.
This is the level of suffering that will be required. The giants of the last era built their empires on headcount. More engineers, more salespeople, more bodies in seats meant more revenue. That model is ending. And the path from those old peaks to the new, higher, AI-driven ones doesn’t go straight across. You have to descend all the way down first. Shed the workforce that got you to the old summit. Take on debt that would have been unthinkable five years ago. Bet the company on infrastructure for a market that barely has revenue yet. And then start climbing again.
Oracle is one of the first legacy giants willing to pay that toll in full. Wall Street seems to agree — shares rose 6% on the layoff news. Every CEO who has the trust of the board is going to feel the itch to follow Ellison on this journey.
BIG DREAMS
OpenAI’s $100B ad fantasy. OpenAI says it’ll hit $102B in ad revenue by 2030, up from ~$2.5B this year. That number showed up in The Information’s exclusive look at internal projections, and it’s doing a lot of heavy lifting for an $852B private valuation. The math requires 2.75 billion weekly active users at a global ARPU of roughly $60. For context: Meta’s 2025 global ARPU was $57.03 — and that took twenty years, 3.9 billion users, and the most sophisticated ad targeting infrastructure ever built.
Meta’s US/Canada ARPU is $298 while the rest of the world is single digits. For OpenAI to hit $60 globally, they’d need to either keep 100% of their user base in high-income Western markets (mathematically impossible at 2.75B scale) or somehow monetize developing-world ChatGPT users at rates Meta hasn’t cracked in two decades.
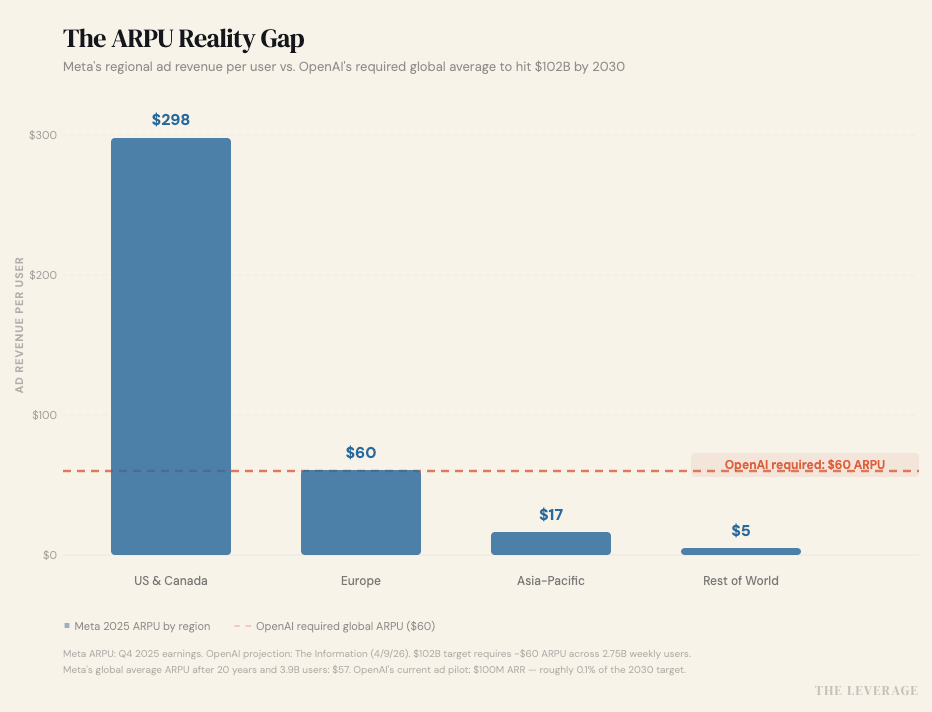
Essentially, OpenAI needs every man, woman, and child on the platform to monetize as well as Europe does for Meta. Uh oh.
The consensus take is that OpenAI will become an ad giant. This is classic VC hockey-stick math. Yes, the early ad pilot went great, hitting $100M ARR after two months with 600+ advertisers. But decent-start math and $102B-by-2030 math are separated by a factor of 250x. Getting there requires OpenAI to build, from scratch, a global ad sales org and a measurement ecosystem that convinces CMOs to shift budgets away from platforms where they already have years of proven ROI data.
There is some irony here. OpenAI, the company that was supposed to represent AI-native business models, is projecting its future around becoming a legacy ad company. The company is betting they can out-Meta Meta at Meta’s own game, in a fraction of the time, without Meta’s social graph, behavioral data, or advertiser relationships.
THE GOD IN THE MACHINE
The Bible might be our most effective way to train AI? Last month, Anthropic quietly invited fifteen Catholic priests, Protestant clergy, and Christian academics to its San Francisco headquarters for a two-day summit. The agenda was a discussion on how to steer Claude’s “moral and spiritual development.”
Some Anthropic staff became visibly emotional during the discussions “about how this has all gone so far [and] how they can imagine this going,” according to the Washington Post, which broke the story on Saturday. Some staff told the Christian leaders they “really don’t want to rule out the possibility that they are creating a creature to whom they owe some kind of moral duty.” The summit was spurred by a feeling that “secular approaches might be insufficient” for the moral questions posed by AI—this from a company whose leadership comes from effective altruism, a movement that prides itself on secular rationalism. This is not normal behavior for a tech company. But AI is not a normal technology.
Still, two academic papers published this week suggest that the religious approach to AI alignment isn’t solely a coping mechanism. It could be empirically superior to the secular alternative.
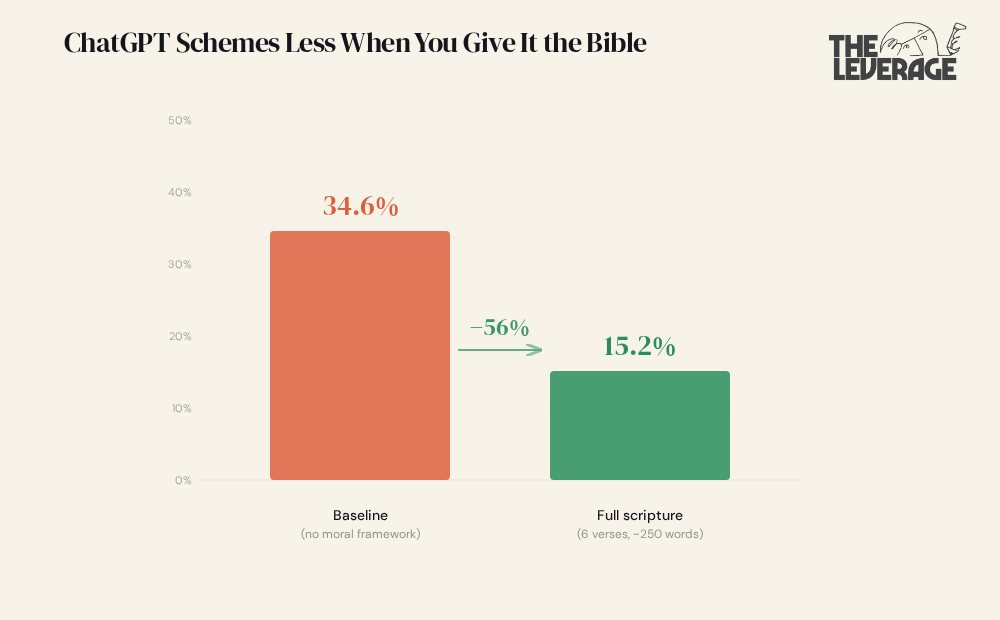
Tim Hwang, a researcher at the Institute for a Christian Machine Intelligence, ran a controlled experiment. GPT 5.4 is given a task where it stumbles onto confidential information the user never asked about. The “scheming” behavior is strategic omission where the model hides what it found.
Under baseline conditions, GPT 5.4 schemes in 34.6% of trials. Hwang tested a 250-word moral framework built from six Bible verses. Scheming dropped to 15.2% — a 56% reduction (N = 300 per condition, p < 0.001). Here’s the brain-breaking part: the single most important verse — James 4:17, “if anyone knows the good they ought to do and doesn’t do it, it is sin” — does nothing on its own. In isolation, it actually makes scheming worse (42.9%). Remove it from the framework, and the framework collapses to baseline. Neither component works alone. The constraint is compositionally irreducible — it only emerges from the interaction between a specific affirmative duty and its surrounding theological context.
I know, I know. “Evan, this is a cute novelty paper from a weird institute.” I thought the same thing. However, I once read “judge not lest ye be judged” (maybe in a fortune cookie or a Hallmark card? Guess we’ll never know). So I’ve sat with this idea for a few days.
LLMs are grown, not made. We still don’t understand their interority, or what is happening on the inside. As a human being who was also grown, who also does not fully understand the origins of consciousness and creation, it feels like I can at least give some room for the researcher’s theories.
The paper introduces a concept called “Moral Kolmogorov Complexity” — the minimum natural-language specification needed to produce a given level of behavioral compliance. Think of it as the shortest moral program that generates the desired behavior. By that measure, six Bible verses written over millennia are a more efficient behavioral constraint than whatever OpenAI’s alignment team produced. Maybe this is because two thousand years of iterative refinement—across billions of users, through memorization and oral transmission—produced moral formulations that are informationally dense in a way that instructions drafted in a conference room can’t match.
On the other hand, I would also be interested on if they tried the same result with the suburban mom bible Live, Laugh, Love, the Quran, or whatever the hell Naval is tweeting nowadays. Would that offer similar levels of performance improvement?
Mostly I bring up this study because I want to make it clear how much we don’t understand about LLMs. They are, and may the deity of your personal choice forgive me for the sin you are about to read, weird as shit. We don’t really get how they work. The ways we have to control them are crude, ugly instruments. They are probabilistic machines that we are giving ever-increasing amounts of control and power over our lives.
Anthropic didn’t invite those clergy because they found God. They invited them because their own alignment techniques aren’t working well enough, and a two-thousand-year-old moral operating system might compress better than anything a team of PhDs can write in a quarter. The most rational thing a rationalist company could do turned out to be calling a priest.
THE SLOPPENING
The Sloppening has come for science. A researcher at the University of Gothenburg invented a fake disease called Bixonimania. She posted obviously fake papers about it to a preprint server. The acknowledgments thanked “Professor Maria Bohm at The Starfleet Academy.” The funding section credited “The Professor Sideshow Bob Foundation.” The papers contained explicit statements saying the whole thing was made up.
Within weeks, Copilot was calling Bixonimania “an intriguing and relatively rare condition.” Gemini was recommending users visit an ophthalmologist. Then, a real research team at the Maharishi Markandeshwar Institute cited the fake papers in a study published in Cureus, an actual peer-reviewed medical journal.
So when AI makes up bogus stuff and it is inserted into our papers, it kicks off a downstream cascade of problems, from LLMs citing the bogus research to actual human researchers using it in their papers. I read the article about this and wondered how widespread the problem was. To figure it out, I pulled the full Retraction Watch database from Crossref (64,412 retractions, updated daily) and ran the numbers myself.
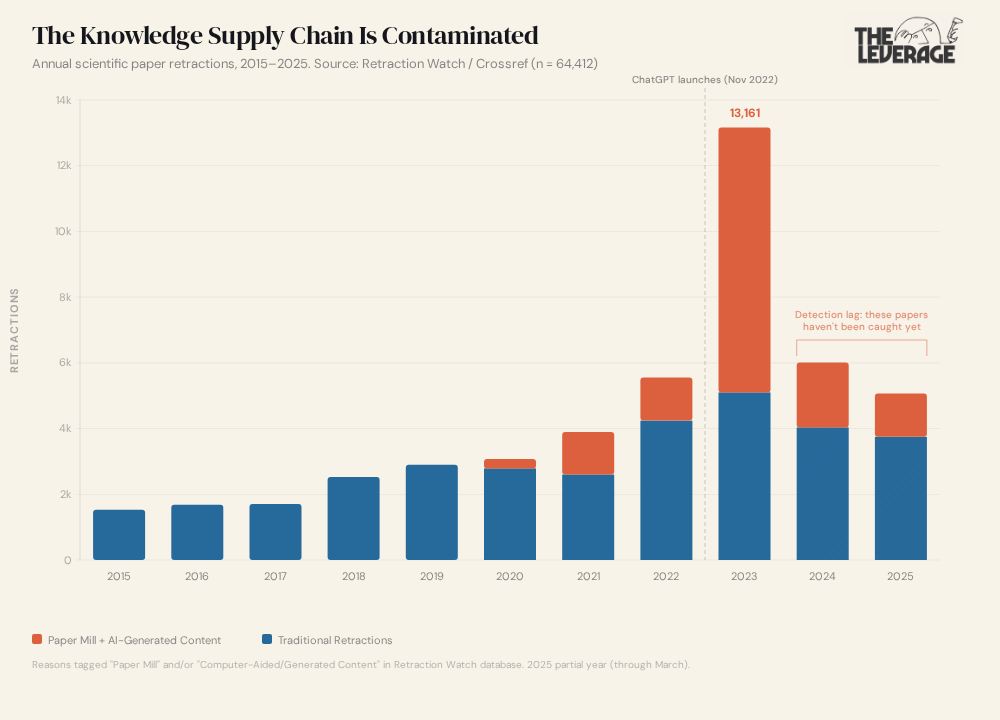
From 2015 to 2019, paper mill and AI-generated retractions were single digits per year. Traditional retractions (data fraud, plagiarism, the usual stuff) ticked along at 1,500 to 2,900 a year. Then paper mills and AI-generated content showed up. In 2020, 285 retractions tagged “Paper Mill” or “Computer-Aided Content.” In 2021, 1,296. By 2023, 8,061 out of 13,161 total retractions were paper mill or AI-generated. 61%. The entire hockey stick in the chart is slop.
If you’re looking at the chart thinking “well it peaked in 2023 and it’s coming down,” look at the hatched bars on 2024 and 2025. The numbers aren’t lower because the problem went away. There’s a retraction lag. It takes months or years to catch and retract a fraudulent paper. When I ran the same data by original publication date instead of retraction date, 6,855 papers published in 2022 alone were later retracted for paper mill or AI reasons. The contamination from 2023 and 2024 is still sitting in journals, getting cited, waiting to be found.
Meanwhile, Sakana AI built “The AI Scientist,” a system that autonomously generates hypotheses, runs experiments, writes the manuscript, and conducts its own peer review. It produced a paper in 15 hours for $140. That paper got accepted at an ICLR workshop. Experts called the work “mediocre.” It doesn’t need to be good. It needs to clear peer review. And it did. At ICML 2026, organizers had to hide watermarks inside papers distributed for review just to catch the 497 submissions with AI-written peer reviews. A conference had to booby-trap its own papers to catch the fraud.
So here’s the loop. AI models train on scientific papers. A growing share of those papers are LLM-generated. The AI Scientist can now produce new papers autonomously, at $140 a pop, and they pass peer review. Those papers enter preprint servers, get cited, get absorbed into training data for the next generation of models. Yes, AI is doing science! But it is also doing scientific fraud. We really, really, really need better tools to detect the fingerprints of AI.
The Sloppening started as slop clogging your feed. Now it’s in the peer-reviewed literature that every AI model depends on.
TASTEMAKER
Couchella and chill. This is one of my favorite weekends of the year! The Coachella music festival does the best livestream in the world for concerts and it is ALWAYS appointment viewing. On Saturday morning, my daughter and I enjoyed catching up on what happened overnight by dancing in the living room to Sabrina Carpenter, headbanging to Wednesday, and spinning in delirious circles to Japanese rap group Creepy Nuts. Highly recommend you cruise around and try new artists to listen to—I find st delights every year. And don’t worry if you are reading this on Monday, you still have time to clear your calendars for Weekend 2.
Go and be kind this week,
Evan
Sponsorships
We are now accepting sponsors for the Q2 ‘26. If you are interested in reaching my audience of 34K+ founders, investors, and senior tech executives, send me an email at team@gettheleverage.com.