

Meta’s Massive Layoffs
The Weekend Leverage, March 15th

This was one of those weeks where the sheer velocity of AI’s impact on business became impossible to ignore. Meta is weighing its largest layoff ever. Anthropic is winning seven out of ten first-time corporate buyers over OpenAI. And when researchers finally stress-tested whether frontier models can do real strategy, the results were humbling.
It sounds bleak, but I actually think the picture is more interesting than it is scary. The revenue-per-employee bar is being violently reset, yes — but that’s also creating a world where a single talented founder can build something that used to require many employees. The models are replacing commodity work, but they’re failing spectacularly at taste, judgment, and long-term thinking—which means the premium on those human skills has never been higher. The people who sharpen those edges right now are going to have the best decade of their careers.
Let’s get into it.
MY RESEARCH

The zero human company. A startup called Polsia is promising what every overworked founder fantasizes about: AI that autonomously builds, codes, and markets an entire company for you—no employees required. With nearly 4,000 AI-generated businesses on its platform and $4M in annualized revenue, it looks like proof that the zero-employee company has arrived. So I put it to the test, feeding it my own business and watching what came out the other side. The result is my argument for why the collapse of creation costs doesn’t make founders obsolete—it just moves the competition to the things AI is worst at. Read here.
Prediction markets have turned gross. Prediction markets were supposed to be truth machines. The research is compelling. Put money on the line and people get honest fast. They’ve been shown to beat polls, expert panels, and economic models at forecasting what’s going to happen next. But something went wrong. Instead of becoming the world’s best information tool, they have devolved into chaotic sports gambling platforms. Worse, the structure creates genuinely dangerous incentives. I think prediction markets are one of the most important innovations in finance and technology. I also think they’re on a path that’s unhealthy for society. Watch here.
WHAT MATTERED THIS WEEK?

BIG TECH
Meta plans to lay off 20% of staff. As I warned last week, you can expect large-scale layoffs from tech giants. Meta is reportedly weighing cuts that would affect roughly 15,800 people out of its 79,000-person workforce. Meta spokesperson Andy Stone called the report “speculative reporting about theoretical approaches,” which is corporate speak for “we haven’t decided the exact number yet.”
Zuckerberg said in January that “We’re starting to see projects that used to require big teams now be accomplished by a single, very talented person,” Two months later, his company is preparing to act on that logic at historic scale.
Two weeks ago I showed you how Block’s 40% layoff brought its revenue per employee in line with AI-native startups. But the full picture is more dramatic than that. The gap between legacy software companies and AI-native startups is a canyon.
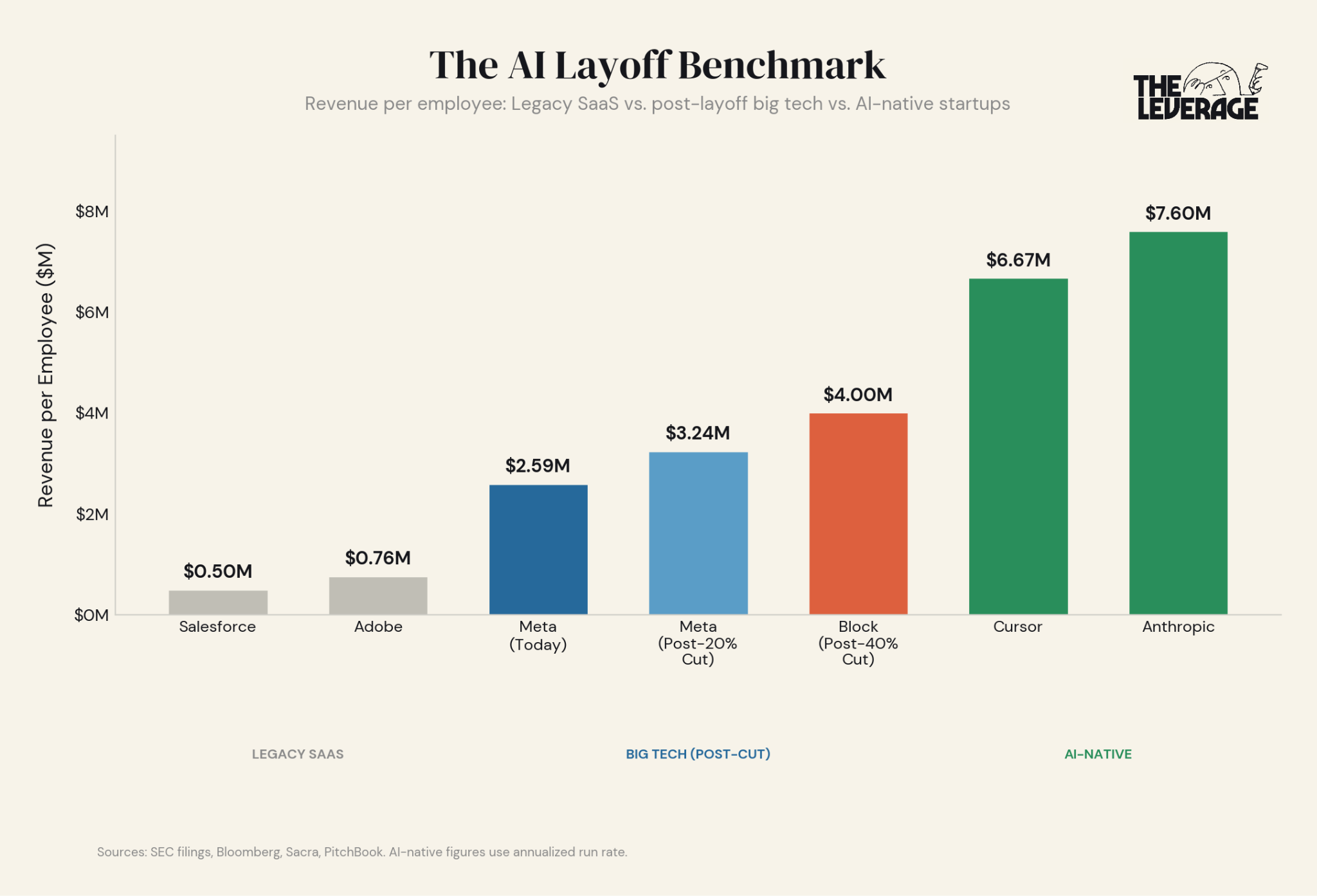
Salesforce generates about $500,000 in revenue per employee. Adobe, $760,000. These are two of the best software companies ever built, and they’re operating at a fraction of what AI-native companies produce. Cursor, which just hit $2 billion in annualized revenue, generates $6.67 million per employee with roughly 300 people. Anthropic is at $7.6 million with about 2,500.
Meta today sits at $2.59 million. Cut 20% and that jumps to $3.24 million. Block, after axing 40% of its workforce, reaches $4 million. Both are still less than half of what Cursor and Anthropic generate per head. Even after one of the largest layoffs in tech history, Meta wouldn’t be halfway to the AI-native frontier. Block had to cut nearly half its company to reach $4 million. Salesforce and Adobe haven’t started cutting at all. Every one of these companies will be citing AI as the reason. Some of that is genuine! A lot of it is convenient cover for pandemic-era overhiring that executives would rather not own.
Founders need to wake up that the revenue-per-employee bar is being reset in real time. Venture capital is a scarce resource and if you want to compete for it and want to get investors excited, these are the new bars you have to clear. (I am very, very glad I chose not to raise money for The Leverage).
BIG LABS
People are dramatically misunderstanding Anthropic’s business. There’s a popular narrative about Anthropic right now: Claude is the coding model. Cursor and the coding agents are reskinning its API, developers love it, and that’s the whole story. New data from Ramp suggests that take is, at best, incomplete.
I sat down this week with Ara Kharazian, who leads the Ramp AI Index. Ramp’s data set is uniquely granular: unlike a credit card network that just sees vendor-level transactions, Ramp sees itemized purchases, broken down by provider, by model, and by whether it’s API spend or chat subscription spend. Here are four numbers that tell the real story.
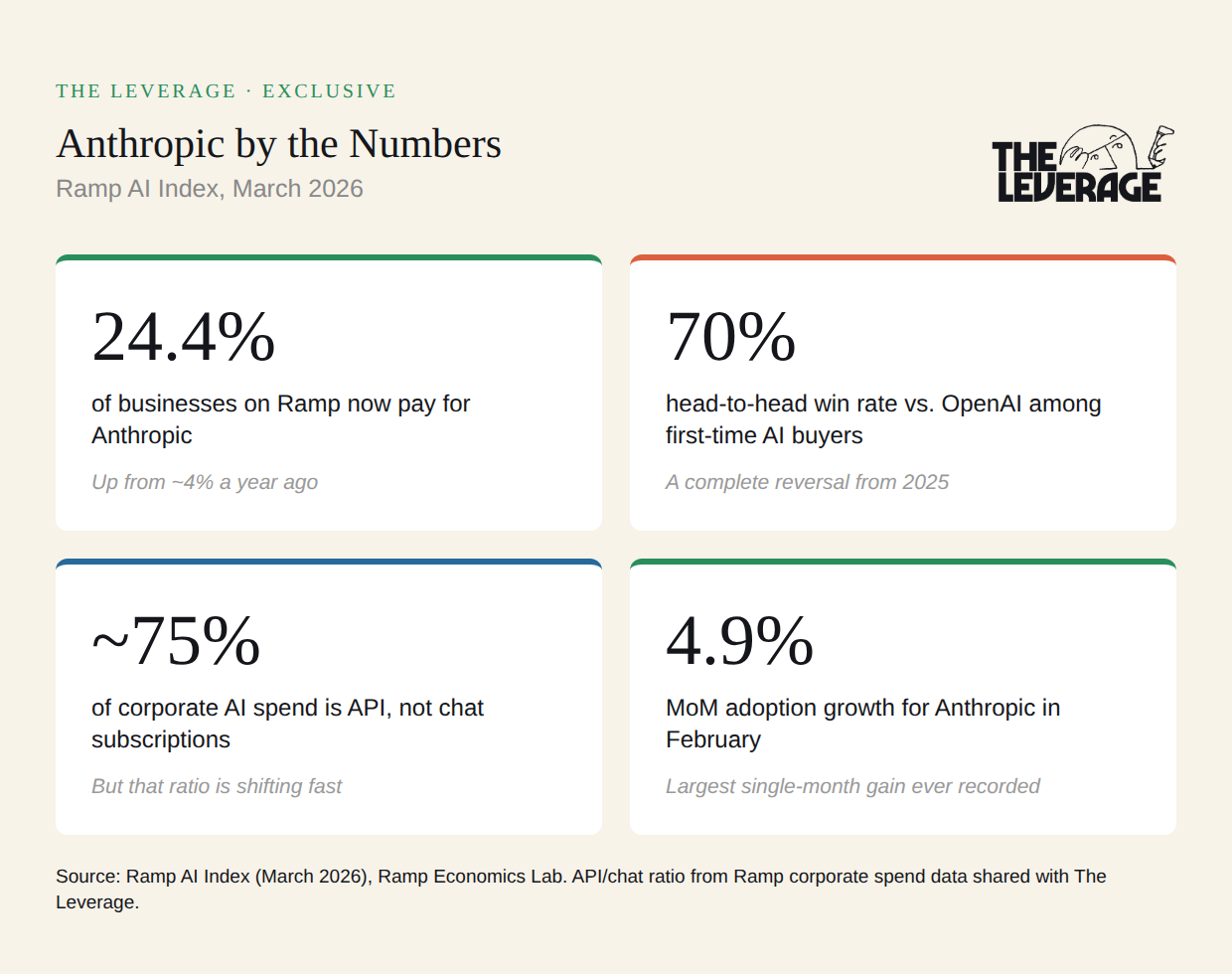
24.4% of businesses on Ramp now pay for Anthropic. A year ago, it was roughly one in 25. Now it’s nearly one in four. Anthropic’s 4.9% month-over-month adoption growth in February was the largest single-month gain since Ramp started publishing the index. Meanwhile, OpenAI’s adoption rate fell 1.5%, the biggest single-month decline for any model company on record.
70% head-to-head win rate vs. OpenAI among first-time buyers. This is a complete reversal from 2025, when OpenAI was the default first purchase for companies buying AI. When a company buys AI for the first time today, it’s choosing Anthropic seven times out of ten.
~75% of corporate AI spend is API, not chat subscriptions. But that ratio is shifting. For most of 2025, Anthropic was almost exclusively an API business. That started to change around December, and by January, Anthropic had captured the majority of corporate chat subscription spend. Ara told me that Claude Code’s launch coincided with a significant adoption surge, but added: “A lot of it isn’t because of Claude Code. I actually think a lot of it is because of Claude Cowork.” If a desktop agent for non-technical users is what’s driving subscription growth, Anthropic is no longer just the developer’s model. It’s crossing over.
Ara told me that even if you strip out the largest whale customers from the data, the API to chatbot ratio trends still hold. The API business is diversified across use cases, and a meaningful chunk of what looks like coding-agent adoption is people going directly to Claude Code.
The “Anthropic is just the coding model” take was always too simple. The data says they’re building a multi-surface business with real consumer traction, a diversified API customer base, and a superior win rate over their biggest competitor. Not bad!
THE SLOPPENING
AI writing is more pervasive than you can possibly imagine. Apple’s 50 year anniversary letter was entirely AI written. A Wall Street Journal op-ed written about the killing of Iran’s Supreme letter last week? Also entirely AI-written. We have crossed the point where it is no longer just some junior marketer using these tools to write crappy SEO copy, but our most powerful elites, publishing important documents, all being done by AI.
Lest you think this is anecdotal data, check out some science. This study, published in October of 2025, looked at 186K articles from 1.5K American newspapers, and found that roughly “9% of newly-published articles are either partially or fully AI-generated.” Again, this is data from summer of 2025. What do you think the percentage is at now? I am willing to bet at least 15%, perhaps 20%.
They also analyzed 45K opinion pieces from the Washington Post, New York Times, and Wall Street Journal, and found that “they are 6.4 times more likely to contain AI-generated content than news articles from the same publications.”
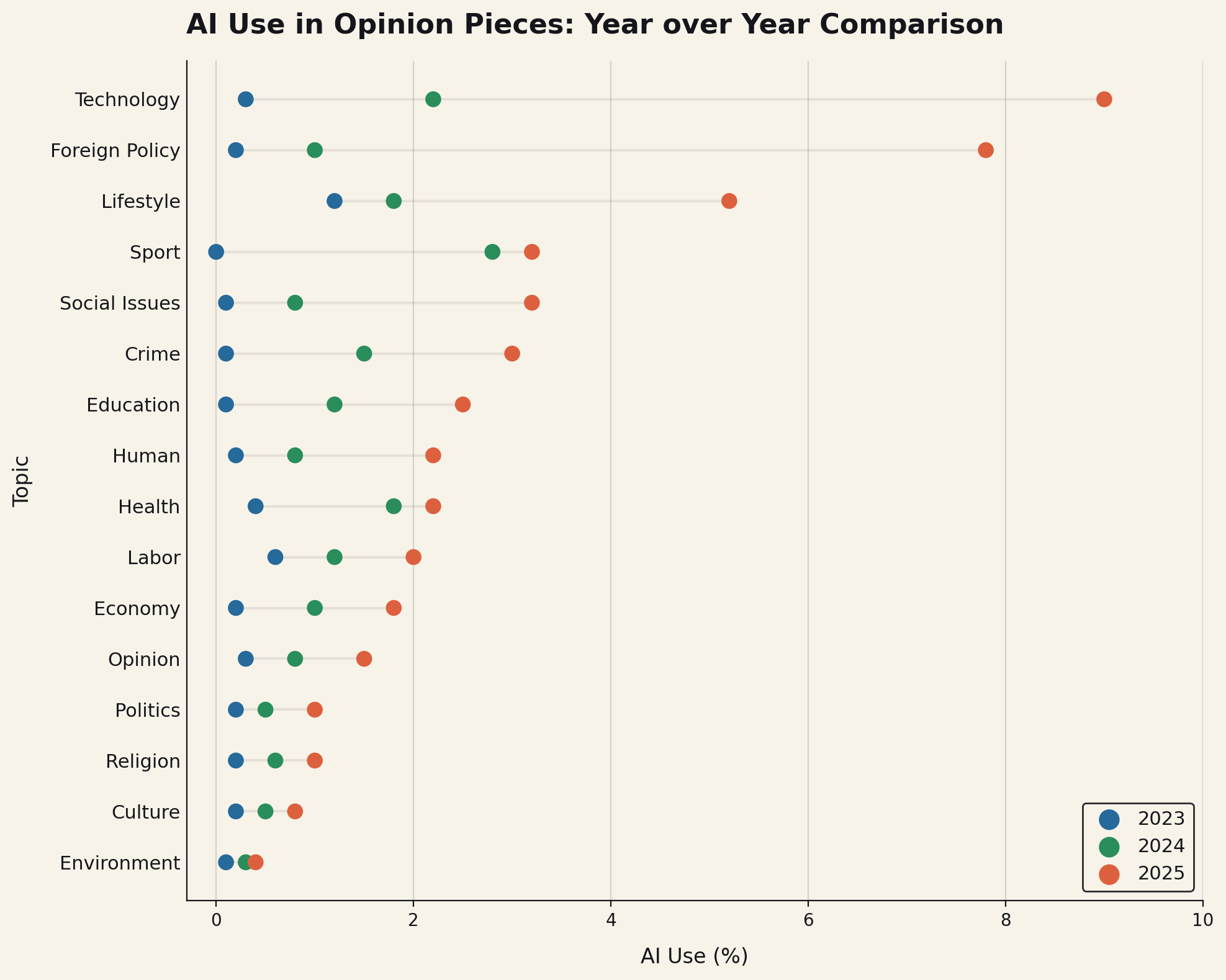
The people who are supposed to be our leading analysts and writers are outsourcing their craft to the models.
Why are they doing this? Simple—the audience can’t really tell and often prefers the AI copy. The New York Times ran an experiment this week putting copies from literary geniuses like Cormac McCarthy against AI generated copy. And, you guessed it, the AI pulled ahead, with 54% of all votes being cast for the AI written copy. There are obvious flaws to this test; AI writing can be beautiful on the individual sentence level, but it fails as the length increases. Comparing similar length passages is not a fair test. Still, it is directionally indicative of where we are going. I would’ve thought that the erudite audiences of our leading media institutions would have more discernment than this.
I am open to the argument that AI writing 100% of a newspaper is fine. Journalists should be cultivating sources and scoops, not wiling away their time on copy. Shoot, I am even open to the thought that 100% AI analysis is fine too. As dire as that would be for my ability to pay for daycare, someday it is likely a model will be better than me at thinking through the problems I write about.
What I mostly worry about are the second order effects of this on society. These models are subtle things; they can shape your thinking in ways that are only obvious in retrospect. If our elites are trusting them with their, and by extension our, most valuable possessions—our intellectual freedom, our attention, and our minds—what does that do? I don’t know if that is a better world or a worse one, but I do know that no one knows the answer to my concern but we are all doing it anyway. The Sloppening originally competed for our attention, but now it competes with the process of thought itself.
AI is truly atrocious at business strategy. Researchers, including an old classmate of mine from college, just published the first real benchmark for whether AI can actually do strategy.
They ran 34 LLMs through the Back Bay Battery simulation, a Harvard Business School staple where you manage a company through a disruptive technology transition over eight years, balancing a profitable but declining core business against an unproven emerging technology.
The results really surprised me—Mid-tier reasoning models from early 2025 (o3-mini, o4-mini, Claude Sonnet 4, Gemini 2.0 Flash) beat the average MBA student at a top business school. But the frontier models like GPT-5 got meaningfully worse, falling below the MBA average.
(It is never a good day when you say the average MBA was smarter than your AI.)
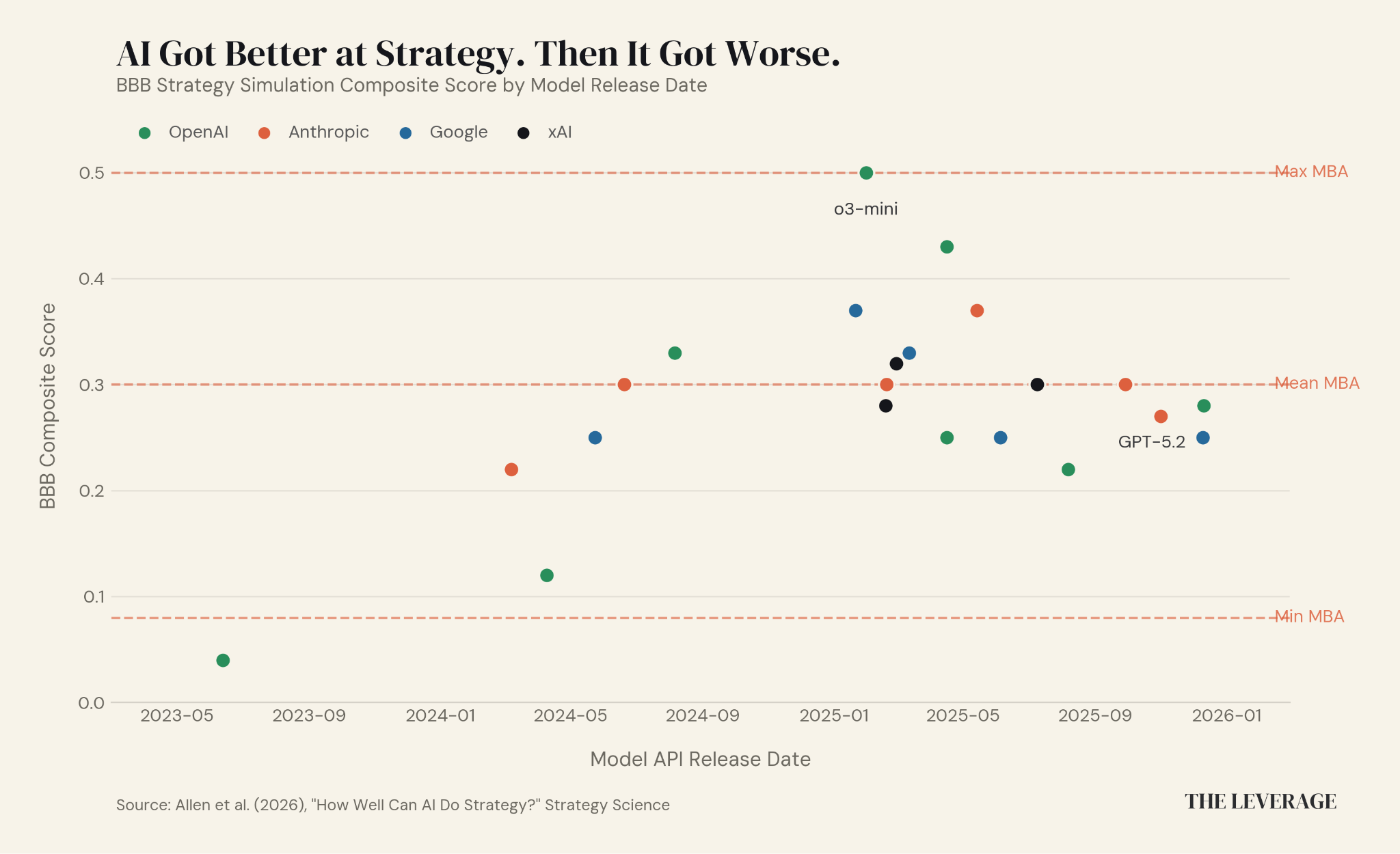
The mistakes they made were pretty basic. GPT-5 would declare things like “Pause all emerging tech R&D due to long lead times and poor fit with current market requirements.” Classic Innovator’s Dilemma behavior, from the models that are supposed to be the smartest.
Even weirder, AI performance on strategy initially improved alongside gains in coding and science benchmarks, then the correlation broke. The models kept getting better at PhD-level physics and competitive programming while getting worse at placing bets under uncertainty. Strategy is about committing resources to uncertain futures with delayed, noisy feedback, and the biggest models default to backward-looking, risk-averse, protect-what’s-working behavior because that is what works in their primary use cases in coding and marketing.
I worry about this in conjunction with my writing point above. We are mistaking the outputs for the process, and it feels incredibly likely that CEO’s are asking Claude for help on how to plan for the future. Since they employ most of us, that seems pretty bad!
TASTEMAKER

The Spectator: A few years ago I climbed a New Zealand mountaintop for a sunrise hike. After hours of sweating and suffering, I anxiously awaited the spiritual high that always accompanies summiting. To my horror, a woman started blaring techno music on a speaker, put on a flouncy dress, and began a 30-minute photo shoot. The moment was ruined. This short film documented this type of phenomenon. Smartphones have changed how we experience natural beauty. The film is also very meta; it is deliberately slow and contemplative—I counted how many times I itched to reach for my phone and it is more than I am willing to say publicly. Free to watch on YouTube.
LCD Soundsystem is a live band: At my first LCD show, I arrived unbaptized. I had never heard a song of theirs in my life. So when the first song ended, I was just slowly swaying and not quite feeling it. Then I made eye contact with a big, muscular guy about 30 feet away from me in the pit—he proceeded to run straight at me, in an almost dead sprint, full-on crazy in his eyes. Right before we were about to collide, he skidded to a halt and grasped my shoulders,
WHAT IS YOUR NAME?
Evan
EVAN. THIS IS THE LAST NIGHT OF OUR LIVES. LET’S DANCEEEEEEEE.
He started jumping up and down, and I went with him. And right in that moment, the band descended into one of the all time great indie dance songs, “Daft Punk is playing at my house.” My friend group merged with his, and we danced like hooligans the entire night. It was one of the greatest live shows I’ve ever been to. My wife and I just bought tickets to LCD’s upcoming shows in Boston and I can’t wait. If you haven’t listened to them before, I highly recommend this concert film from 2011.
Go and be kind this week,
Evan
Sponsorships
We are now accepting sponsors for the Q1 ‘26. If you are interested in reaching my audience of 34K+ founders, investors, and senior tech executives, send me an email at team@gettheleverage.com.
Really great read, thanks for sharing.
"The results really surprised me—Mid-tier reasoning models from early 2025 (o3-mini, o4-mini, Claude Sonnet 4, Gemini 2.0 Flash) beat the average MBA student at a top business school. But the frontier models like GPT-5 got meaningfully worse, falling below the MBA average."
I'm actually not that surprised to read this. It was pretty clear GPT-5 was an instant and obvious downgrade for my purposes when it was released and that was the moment I pivoted the bulk of my usage of OpenAI. Part of me has always felt that while advances in the models since last summer have definitely brought improvements in say, agentic coding, they are tangibly worse at a lot of things than models like 4.1, o3, o1-pro, even the original 3.5 sonnet, excelled at. This is particularly true for OpenAI's models, Anthropic's have not seen nearly as much of a drop off.
The reason you cited (included below) makes a lot of sense to me. But how much of this would you speculate is due to the need to manage cost / compute demand? Is it possible the older models were genuinely more capable in some ways but too expensive to run at scale given current demand levels relative to hardware capacity? o1-pro was fantastic at helping me reason through generalist problems (with real world results to back it up) but is literally 100x more expensive than GPT-5.
"Strategy is about committing resources to uncertain futures with delayed, noisy feedback, and the biggest models default to backward-looking, risk-averse, protect-what’s-working behavior because that is what works in their primary use cases in coding and marketing."
Add to that, there's probably no real business incentive to fix this. These companies make their money when enterprises adopt the models for high-volume, measurable work (code, marketing copy, customer support) tasks where you can show a productivity gain in a quarterly deck. Nobody is going to optimize a foundation model for "makes good bets under uncertainty" when they could optimize for "writes better React components," because one of those shows up in procurement conversations and the other doesn't. So this gap might get worse, not better, as the industry matures. And the CEOs reading the output are generally not the people who are going to catch it.
It's an interesting result the researchers got in the study you mentioned. I use it all the time for long-term planning but realize it's going to tell me what I want to hear. There are a few techniques I've found that help. Have it take the persona of famous people with a distinctive view that's been documented on the internet and forcing it into real trade off situations. I've suggested to a few writers with a distinctive or contrarian style that they should offer an MCP connector to their work. You get an insight into how people use it and I get to plug your thinking into my process. Win win.